Building a Reliable, Agent-Driven Narrative Engine for Intent AI’s AiRICA
Wippy
Agent Chain
GPS-Anchored
Narrative
Client
Independence
Solutions
Industries
Technologies

About the Project
Intent AI’s AiRICA is built on a category-management methodology that took 25 years to develop. The methodology was sound. The delivery was not. Every client engagement required a data-science team to manually stitch together four different datasets: a consumer survey, syndicated POS data, panel-leakage data, and a retailer SKU export. The result had to become a single category growth story. The GPS framework that should have connected every analytical layer existed only in the team’s heads. The output was being rebuilt in Excel and PowerPoint after every engagement.
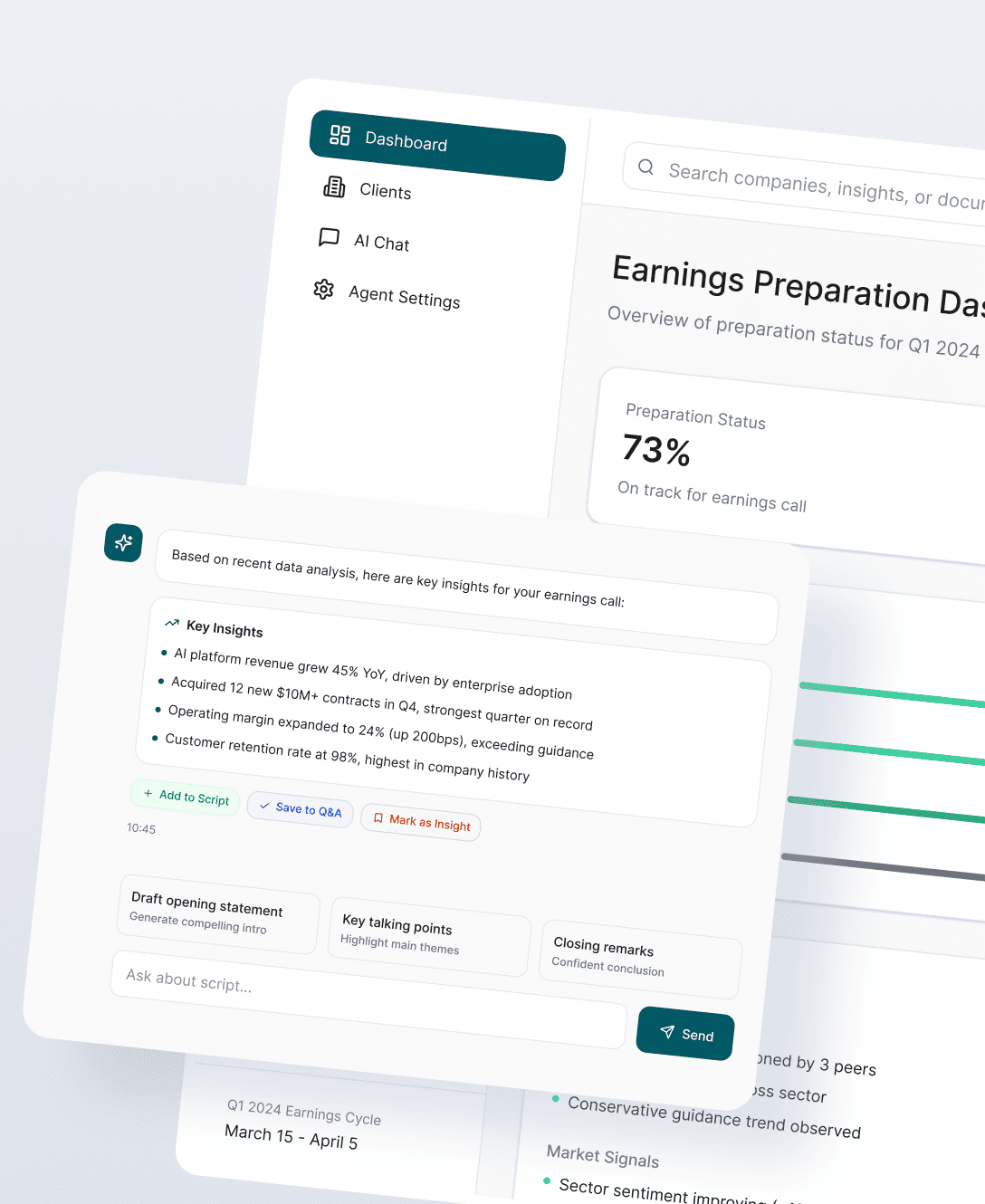
Spiral Scout shipped a standalone narrative engine on Wippy that runs Intent AI’s methodology as a set of durable agents. The engine carries the GPS thread from consumer survey data all the way down to individual store slot allocation and produces a connected category growth story without a data-science team in the loop. The first production run used real mattress retail data. The same engine is now demoed to clients and investors as the architecture for how AiRICA scales.
Objectives
- Ship a standalone narrative engine on Wippy with its own data store, with zero dependency on AiRICA’s existing backend, chat UI, or cloud environment.
- Carry the Growth Potential Segment thread through every analytical layer, Strategy, Planning, and Execution, so the output reads as one story, not four disconnected analyses.
- Cross-reference four structurally different datasets through a canonical schema that joins on store and item IDs.
- Encode Intent AI’s editorial rules as per-agent guardrails so the system stays on-methodology and does not prescribe actions at steps where the methodology only calls for description.
- Produce a visual prototype with an auto-generated slide-deck view and document export, suitable for client and investor presentations.
- Train the Intent AI team to refine agent prompts, knowledge base content, and narrative thresholds without filing engineering tickets, as an explicit contractual deliverable.
- Deliver architecture documentation covering the integration path for future connection to AiRICA’s backend via API.

Challenges
Solutions
Four Datasets, Four Vocabularies, One Story
AiRICA handled questions inside a single dataset well. It broke at the join. Consumer language had to reconcile with retailer SKU language and syndicated manufacturer data. Layering another LLM prompt on top of the existing chat surface produced narratives that sounded plausible but contradicted the underlying numbers. The team was rebuilding the story by hand after every client engagement.
Canonical Schema and GPS-Anchored Agent Chain
We built an ingestion layer that maps each source to a canonical schema and joins on Item ID rather than item name, with the unmatched long tail treated as unmapped so it does not contaminate the analysis. On top of that, a chain of Wippy agents each owns a specific analytical question and writes its findings back to a shared state. The narrative agent reads that shared state. The GPS framework is the spine: every agent filters through the same shopper definition, so the same segment appears in slotting, store-level variance, and the final recommendations. The thread does not break between steps.
A General-Purpose LLM Prescribes Where the Methodology Says Describe
Intent AI’s methodology has explicit rules about when the system can recommend and when it must stay descriptive. A general-purpose LLM ignores those boundaries. It starts prescribing in the Market and Consumer Insights step, which destroys credibility with category managers who know the methodology and know better.
Editorial Rules Encoded as Per-Step Agent Prompts
We pulled the client’s editorial rules directly from their Demo Business Questions library and encoded them as system prompts for each agent. Every agent knows where in the 13-step process it sits, which tone it owns, and what it is not allowed to say. The opportunity-sizing logic is the clearest example: the recommendation agent does not rank perception gaps by raw size. It weights them by attribute importance and the economic value of the affected shoppers. The guardrail came directly from the client’s source materials, not from a general prompt.
Real Data, Real Deadlines, Clean IP Boundary
Intent AI had two hard dates before a full backend integration was feasible. They also needed a path to keep refining the system after handoff without burning engineering hours, and an unambiguous boundary between Spiral Scout’s framework code and Intent AI’s deliverables.
Standalone Engine, Work-Made-for-Hire Deliverables, Three Operator Sessions
The build was scoped as a standalone service with its own data store. AiRICA’s existing backend is untouched. All deliverables transfer to Intent AI as work-made-for-hire upon payment. The underlying framework tools remain licensed for the lifetime use of the deliverables. Three working sessions were scoped for output review, prompt adjustment, and narrative threshold tuning, with the explicit goal that the client can run routine refinements without a Spiral Scout engineer in the loop.
The Dataset Was a Real One, Not a Clean Test File
The data had every pattern Intent AI’s pipeline will see in production: inconsistent column layouts, multi-tab structures, and SKUs that exist online but not in store.
Schema Hints Over Auto-Modeling, Store ID as the Join Key
Rather than trust generic auto-ingestion, we wrote explicit schema rules for each file: confirmed column positions for Slot Productivity, Stores Not Selling, Units, Sales, Slots, and their percentage counterparts. We joined on Store ID across files to recover human-readable store names without string-matching. The agent flags web-only SKUs for exclusion from in-store analysis.

Strategy
We treated this as a production-judgment problem, not a UI build. The constraint was never “make the demo look better.” It was: carry the GPS thread reliably from a consumer survey all the way down to a single store’s slot allocation, and leave the client able to tune it themselves

De-Risk the Data Foundation Before Any Agent Sees a Prompt
Before a single workflow ran, we mapped all source files end-to-end: exact column positions, join keys, status flags, and known data-quality patterns. The ingestion pipeline gets explicit schema hints for complex layouts so the agent does not have to infer the shape of a multi-tab sheet. This is unglamorous work. It is also the difference between a demo and a system that runs every Monday.

Encode Methodology as Agent Configuration, Not Prose
The client’s Demo Business Questions library, analytic plan, and segmentation diagnostics were converted into structured configuration: which agent owns which question, which dataset it requires, which visualization it produces, and what it is not allowed to say at that step. The narrative engine is steerable by Intent AI because the rules sit in a configuration surface they control, not buried in code that requires a developer to touch.

Ship to a Forcing Function, Not a Roadmap
We prioritized delivery against the client’s hard dates. Work not promised in the SOW was scoped but explicitly blocked on dependencies outside the engagement. Nothing was over-promised.
Project Results & Impact
What exists now that did not before: a Wippy-based narrative engine and a visual prototype that take Intent AI’s four source datasets, run them through a GPS-anchored agent chain, and produce a connected category growth story with specific operational implications. The same engine that ran the pilot narrative is now running real retail data for a client deliverable and the planned demo to leadership. Intent AI’s delivery team can produce that output without rebuilding it by hand.
Tangible Outputs:
– Working narrative engine on Wippy, demoed to Intent AI on real pilot data.
– Category Growth Plan deliverable produced from the live dataset.
– Technical specifications covering the four-tab architecture and the data-foundation work.
– A documented connection between GPS segment behavior and concrete operational levers, framed as a category-authority gap rather than a store-convenience problem.
– Architecture documentation covering the integration path for future connection to AiRICA’s backend via API.
Key Takeaways
- The Spiral Scout difference is encoded judgment, not a chat box. The 25 years of methodology that the Intent AI team built is preserved as agent guardrails: what each step can recommend, which tone it owns, which dataset it can reach for. Not left to a general-purpose LLM to improvise.
- A canonical schema and one join key do more architectural work than any model choice. Most of the failure modes Intent AI was seeing in production were data-foundation failures dressed up as AI failures. Fixing the join fixed the narrative.
- Client independence was a contractual deliverable, not an aspiration. Three operator training sessions, an editable knowledge base, and a configuration surface for narrative thresholds mean the client can refine the system without Spiral Scout in the loop.
- The architecture is transferable. The same agent chain ran the pilot and is now running a different retail category with a different volume driver, the same methodology, and the same engine.
Worth thinking about if you are building a methodology-driven analytics product on top of messy, multi-source enterprise data.

I’m impressed by Spiral Scout’s ability to understand our business in detail to improve our solution week by week.
OVERALL SCORE
At Spiral Scout, we believe that when it comes to software development and delivery, it’s time for a change.
5.0
SCHEDULING
On Time / Deadline
5.0
QUALITY
Service & Deliverables
5.0
COST
Value / Within Estimates
5.0
NPS
Willing to Refer