
Your Expertise Belongs in a System, Not a Person’s Head.
The breaking point is always the same: the business outgrows the people holding it together. Whether that means a founder who cannot scale their domain expertise into a working product, or a firm whose critical decisions live in a handful of senior heads, we build the infrastructure that closes that gap. Today that means AI agent systems built for production, not demos. You own it when we are done.
Where Expertise Becomes Infrastructure
Every solution below is a production engagement. No pilots, no decks, no demos that stop working after the call.
AI & Automation
The firms that fall behind are not the ones that lack good people. They are the ones whose best people are the bottleneck. If your senior team's decisions, judgment, and institutional knowledge are required for every non-trivial workflow, you have a system problem, not a staffing problem. We encode that expertise into AI agent systems and rules engines that run reliably, handle real load, and keep working whether or not the person who built the process is in the room.
AI Readiness Audit
AI Strategy & Architecture
Agent Automation
Knowledge & Rules Engine
Workflow Orchestration (Temporal)
Agentic AI with Temporal
-


Salesforce AI Integration for Fortress (Legal SaaS)
Link
Custom Software & Platforms
You know your market better than any generalist can. What you need is the infrastructure to match. We build production-grade products from discovery through handoff for domain expert founders who need a system that ships fast, handles real users, and transfers to their team without ongoing dependency on us. No fragile prototypes. No build-and-leave. A product you own.
-


Turning Complex Quoting into Controlled, Repeatable Systems
Link
Strategy & Execution
Most engagements fail before a line of code is written. The problem is usually a missing architecture decision, an unclear entry point, or a scope that was never pressure-tested against production reality. This is where we start when you know something needs to be built but are not sure what, where, or in what order. We diagnose before we prescribe, and we will tell you if the build is not worth doing yet.
Technical Co-Founder
Product Discovery
Product Design
Mobile App Development
Quality Assurance & Testing
Dedicated Teams
Support & Maintenance
-
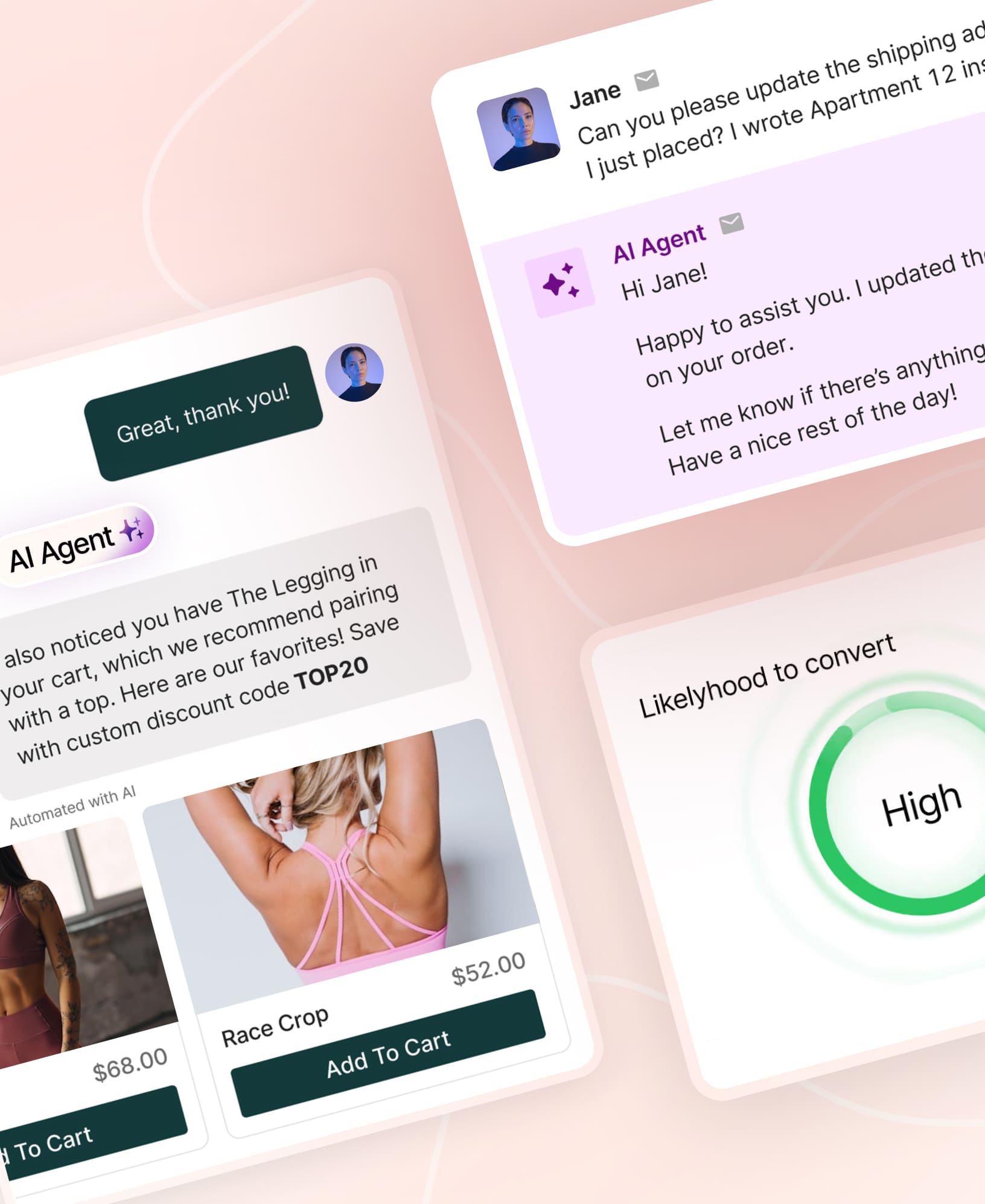

AI Agentic Automation for E-Commerce Support
Link

From First Call to Full Ownership
Diagnose Before Building
Before any code is written, we identify where the knowledge, logic, or workflow actually breaks and what the right entry point is. Most projects fail here because someone skipped this step.
Scope and Build for Production
We define the system based on what needs to run under real load, not what works in a demo. You see working output from the first sprint and own every piece of IP as it is built. No lock-in, no shortcuts that create dependency later.
Clean Handoff, No Dependency
When the engagement closes, the system runs without us. You get full documentation, clean IP transfer, and architecture any competent engineer can extend. We stay available if you want us. You are never dependent if you do not.
-

Everyone from Spiral Scout was professional, knowledgeable, patient (steep learning curve for us), caring and went above and beyond to make sure we were thrilled with the final result.
-

Spiral Scout truly cares about the end results.
 Matt TormanZoom, Content Marketing Manager
Matt TormanZoom, Content Marketing Manager -

Spiral Scout really knows the Shopify ecosystem and keeps their promises regarding the project’s scope and delivery.
 Chip MaltMade In Cookware, CEO
Chip MaltMade In Cookware, CEO -

Kudos to the Spiral Scout team on the mobile app. The app has gone from ~2.5 in the prior release to 4.7 stars now (and growing) with over 26k reviews on the App Store.
 Jon BreligOn The Snow, CTO
Jon BreligOn The Snow, CTO -

As our application’s complexity increased, the Spiral Scout QA engineers stepped up, managing the details with a proactive and self-driven approach. They’ve been instrumental in filling knowledge gaps and ensuring we stay aligned with our objectives.
 Hector BorgesFound, Director of Engineering, Growth & Consumer Experience
Hector BorgesFound, Director of Engineering, Growth & Consumer Experience -

Spiral Scout did a great job of translating business goals into development requirements and building exactly what I needed.
 Bill CummingsTRUSTR, CEO
Bill CummingsTRUSTR, CEO





The Founder Takes the First Call
Every engagement starts with John Griffin, Spiral Scout Co-Founder, not a sales rep. He has seen most of these problems before and will tell you what is worth building and what is not, before anyone touches a line of code.

Actionable Insights. Delivered.
Stay in the know with expert takes, emerging trends, and practical strategies straight from the front lines of innovation.
-
Wippy Platform: The Intelligent Application Runtime

Wippy Platform: The Intelligent Application Runtime
-
Your AI Pilot Worked. Here’s Why the Production System Won’t.

Your AI Pilot Worked. Here’s Why the Production System Won’t.
-
Claude managed agents vs Wippy: rent the rails, or own the runtime?

Claude managed agents vs Wippy: rent the rails, or own the runtime?
-
Encode Your Firm’s Expertise Before a Competitor Does

Encode Your Firm’s Expertise Before a Competitor Does
-
The Missing Layer Between Your AI Agent and Production

The Missing Layer Between Your AI Agent and Production
-
Your AI Demo Works. Your AI Project Will Not. Here Is Why.

Your AI Demo Works. Your AI Project Will Not. Here Is Why.
-
How to Deploy AI Agents That Actually Work Inside Your Company

How to Deploy AI Agents That Actually Work Inside Your Company
-
AI Agent Governance Is an Architecture Problem, Not a Policy Problem

AI Agent Governance Is an Architecture Problem, Not a Policy Problem
-
The 200-Email AI Disaster: Why Agent Architecture Matters

The 200-Email AI Disaster: Why Agent Architecture Matters
-
How to Build a Knowledge Base for Agents

How to Build a Knowledge Base for Agents
-
Agentic AI Architecture: How Enterprise AI Agents Actually Make It to Production

Agentic AI Architecture: How Enterprise AI Agents Actually Make It to Production










Your questions, answered
If you are a founder building a product around your domain expertise, start with a one-week discovery and architecture sprint, and you leave with a production roadmap and a scoped first build. If you are an established team trying to capture institutional knowledge or automate high-cost manual workflows, start with an AI Readiness Audit. Same format, same outcome. Either way, no one writes code until we understand the real constraints.
The discovery and architecture sprint takes one week. A focused production build on top of that typically ships in six to twelve weeks depending on complexity. The first working system, not a prototype but actual production code, is visible inside the first sprint. We do not quote timelines before understanding your actual constraints. Anyone who does is guessing.
Those tools get you to a demo fast. The problem shows up when the system needs to handle failures gracefully, manage state across long-running workflows, isolate data between tenants, or handle more than a handful of concurrent users. That is where most teams hit a wall they did not see coming. We build the orchestration layer, error handling, and audit infrastructure those frameworks leave out. The result runs under real load, not just in a development environment.
Most firms deliver strategy and hand off implementation to someone else. We build and ship the system. The architects who designed it and the engineers who built it are the same people you talk to in discovery. There is no handoff to a delivery team. When something breaks in production, the person accountable is the person who wrote the code.
The wall is almost always the same: the 80 percent of infrastructure work that looks straightforward until it is not. State management, retry logic, multi-tenant isolation, observability, and production hardening are not things you bolt on later. They have to be designed in from the start. Internal teams hit this wall because they are learning it in real time. We have already built and debugged these systems across dozens of production engagements. The one-week discovery sprint tells you whether your current approach is recoverable or needs a different foundation entirely.
Tell Us Where You Are Stuck
Meet the founders
Tell us your goals
Receive a proposal
Project kickoff

John Griffin
Co-Founder, CEO

Anton “JD” Titov
Co-Founder, CTO
“Anton is an exceptional technologist. I would feel comfortable having him work on any technical challenge.” – Ryland Goldstein, Head of Product, Temporal